

Ultra Ethernet Consortium (UEC) continues to progress towards its v1.0 set of specifications. These specifications will provide implementors with a recipe for deploying the latest innovations in datacenter network technologies to best serve AI and HPC workloads. As UEC preserves existing AI frameworks and HPC library APIs, it is expected that existing workloads can migrate to UEC with no changes required.
As outlined in the UEC 1.0 Overview white paper, UEC endeavors to optimize AI and HPC workloads by modernizing RDMA (Remote Direct Memory Access) operation over Ethernet. The UEC Transport (UET) accomplishes this goal by offering multiple innovations that enable higher network utilization and lower tail latency, both of which are critical for reducing AI and HPC job completion times.
As AI models and HPC workloads continue to grow in size, larger clusters are needed, and therefore, the network performance increasingly becomes a limiting factor. In addition, the network’s contribution to power consumption and overall TCO continues to creep upward. A modest investment in UEC networking technology will provide a quick return on investment.
UEC stack overview: UEC follows the familiar layered approach from broadly deployed AI frameworks and HPC libraries, through libfabric and *CCL libraries to UEC Transport (UET) to Ethernet. This approach is familiar to all networking engineers and preserves all of Ethernet’s software and tools. These UEC APIs also promote interoperability while allowing space for vendor differentiation.
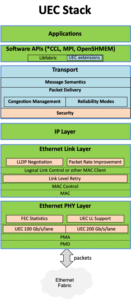
The UEC stack simplifies networking software and improves its performance. By selecting libfabric as its north-bound API, the UEC stack is designed to integrate into existing frameworks, where libfabric is commonly utilized. Worth noting are two key aspects of the UEC stack:
- RDMA operations are optimized to better match workload expectations, minimize hardware complexity, and reduce state.
- Ultra Ethernet Transport (UET) provides multiple transport services that augment RDMA hardware and accomplish the key goals set out in the UEC 1.0 Overview white paper.
Some of the key features described in the white paper are:
- Multi-path packet spraying
- Flexible ordering
- “State of the art”, easily configured congestion control mechanisms
- End-to-end telemetry
- Multiple transport delivery services
- Switch offload (i.e., In-Network Collectives)
- Security as a first-class citizen co-designed with the transport
- Ethernet Link and Physical layer enhancements (optional)
Multi-path packet spraying: UET provides for multi-path packet delivery and fine-grained load balancing through packet spraying. Under UET, every flow may simultaneously use all paths to the destination, achieving a balanced use of all network paths. Rather than relying on a simple ECMP hash to select network links, load imbalances are avoided by the coordinated choice of the paths throughout the fabric between endpoints and switches, guided by real-time congestion management. This fine-grained load balancing results in improved network utilization and reduced tail latency.
Flexible Ordering: The UEC stack provides a libfabric API that allows applications to express workload-specific requirements for message and packet ordering and directs UET’s choice of appropriate transport services. For instance, an AI collective comprised of many packets can be considered a ‘bulk transfer’ where the application is only interested in knowing when the last part of a given message has arrived at the destination. However, the multi-pathing used to improve load balancing may result in out-of-order packet reception. The simple re-order buffer used by other technologies to compensate for this behavior adds cost, latency, complexity, and power. UET, in contrast, offers an innovative solution coupling multi-pathing, flexible ordering, and congestion control to enable an efficient receiver endpoint implementation without requiring a re-order buffer. UET’s use of Direct Data Placement (i.e., Zero Copy) on a per-packet basis is one of the mechanisms that enable an efficient implementation.
Congestion handling: Large-scale AI clusters and HPC networks create unique traffic patterns that require significant improvements in traditional datacenter network congestion handling, especially as the network speeds and bandwidth demands of accelerators increase. Dedicated AI/HPC networks with microsecond-level round-trip times, parallel processing applications, and systolic coordinated multi-flow traffic call for an innovative sender-based congestion control approach.
Network optimization for essential collectives like AllReduce and All-to-All is critical for reducing job completion time. To provide the highest network performance for these collectives, coordinated congestion control over multiple paths is vital to guide packet spraying. Here again UET offers an efficient and scalable solution: For example, All-to-All collectives can lead to incast events where the final switch before a receiver suffers from persistent traffic overload. To avoid these scenarios, UET defines an optional receiver-based congestion control that allocates credits to the senders, thereby augmenting the base sender-based congestion control.
Recognizing that a UEC-compliant network may need to support different libfabric request types simultaneously, another area that sets UET apart is its ability to perform excellent congestion control when some traffic is sprayed and some is not. This can occur, for example, when mixing single-path and multi-path traffic UET transport services (described below).
Telemetry: Congestion handling is assisted by Explicit Congestion Notification (ECN), which is broadly supported by datacenter switches and will now be further assisted by UET’s innovative endpoint congestion mitigation algorithms. UET also adds optional support for switch-based advanced telemetry that shortens control plane signaling time, enabling fast sensing of and reaction to short congestion events. This fast reaction time is particularly important with higher link speeds since congestion events can occur much more rapidly and may have a much shorter duration.
An example of this advanced telemetry is UET’s use of packet trimming, where compliant switches truncate or “trim” a congested packet (rather than dropping it) and send the packet header plus relevant congestion information to the receiver. This strategy conveys precise and timely information about lost packets to the receiver endpoints, resulting in faster relief of incast-based congestion. By coupling this mechanism with a more focused response to congestion events using Selective Acknowledgments versus the traditional heavyweight Go-Back-N approach, the response to congestion and loss is faster and more bandwidth efficient. In the case where a packet is dropped, the use of Go-Back-N, employed by older RDMA technologies, requires the sender to retransmit a long sequence of packets that may be already on their way to the receiver or even received.
Multiple transport delivery services: Application requirements determine the selection of the appropriate UET services. UET offers multiple distinct transport services including:
- Reliable Ordered Delivery (ROD): ROD delivers all packets associated with the same message in order and preserves inter-message ordering. It is designed for applications that require message ordering (e.g., MPI’s match ordering or OpenSHMEM put-with-signal semantics), while benefiting from the congestion control and security enhancements of UET.
- Reliable Unordered Delivery (RUD): RUD is designed to enable operations where packets must be delivered to the application only once but can tolerate packet reordering in the network (e.g., large collectives). RUD’s innovative AI-optimized approach enables multi-path packet spraying by handling out-of-order delivery at the receiver without requiring a re-order buffer, resulting in high network utilization and minimal tail latencies.
- Reliable Unordered Delivery for Idempotent operations (RUDI): RUDI is designed for the highest-scale applications. The application’s semantic guidance here is that the final outcome for the application will not change if packets are received and written into the application’s buffer more than once (idempotency means that applying an operation multiple times will not change the final result). Therefore, RUDI allows packets to be delivered multiple times to the receiver before the whole message is received. The motivation for RUDI transport service is to minimize the state required at the receiver and thereby achieve higher scale. It is most suitable for operations like bulk payload delivery that need the fastest delivery at scale but minimal additional semantics.
Switch offload (or In-Network Collectives): UEC defines the mechanisms needed to offload collective operations (e.g., AllReduce) to the network. This improves bandwidth utilization and minimizes the execution time of some collective operations. The completion of collective operations gates the next computing phase in many AI or HPC jobs. While optional to implement, switch offload may provide application-level performance improvement, not just network-level improvements. When UEC v1.0 is available, it will be the first time such a technology is offered and standardized over Ethernet links!
Security: The UEC Transport layer co-designs security along with the transport services to address threat models while offering an efficient and economic solution to message integrity, confidentiality, and replay prevention. Note that security may present a scalability challenge given the expected speed and size of UEC networks. Therefore, specific attention is paid to minimizing overhead and key management at-scale, for example, by providing efficient group keying mechanisms. With potentially hundreds of thousands of endpoints and link speeds of 1.6Tb/sec imminent, scalable key management becomes a requirement.
Profiles: While AI and HPC workloads are converging, they continue to have some different requirements. Most AI workloads produce large messages and are bandwidth-sensitive, while many HPC workloads are dependent on message ordering, produce very short messages, and are very latency-sensitive. Under MPI, HPC is more packet and message-order sensitive. Recent AI inferencing workloads can be more latency-sensitive than AI training. The extreme bandwidth required by AI demands highly optimized NICs (Network Interface Cards), where die size, power, and state management must all be considered. Therefore, UEC offers multiple profiles to address the different workload needs. Each profile is an aggregation of transport services, libfabric APIs, and required features that best suit the workload. Profiles allow for product flexibility and optimization, promote interoperability, and enable vendor differentiation.
Ethernet layer compliance: The UEC architecture is designed to be compliant and interoperable with existing Ethernet switches. However, UEC specifies additional optional extensions to improve support for AI and HPC. For example, UET supports Link Level Reliability (LLR). In typical high bandwidth-dense environments, common to AI deployments that are sensitive to tail latency, if one link suffers from sub-optimal performance (e.g., due to intermittent higher bit error rates (BER)), it can slow down the entire parallel application. LLR offers fast hardware-based reaction, mitigating link performance issues.
Lossy and lossless networks: While UET provides excellent performance on lossy networks, leveraging multi-pathing and improved congestion control assisted by network telemetry, it is also architected to run on lossless networks. In fact, it makes those lossless Ethernet networks easy to tune and avoids creating congestion spreading that otherwise has been a concern for lossless networks.
What makes a UEC device a UEC device?
Consistent with the industry trends of the last two decades, UEC’s key innovations are at the endpoints. UEC-compliant networks must have endpoints that support UET (i.e., complying with the relevant UET modes and APIs as defined and summarized by one of the UEC profiles). Support of a UEC profile brings together simplified RDMA, multi-pathing with zero copy, higher network utilization, and reduced tail latency, all resulting in the lowest AI and HPC job completion times.
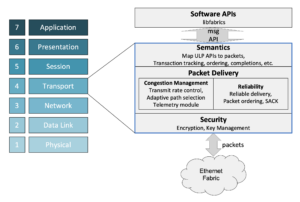
As mentioned above, UET can run over existing datacenter switches but will perform even better with the support of the advanced telemetry and UEC-enhanced Ethernet, transport, and software layers.
The Growing UEC Community
UEC is now a large consortium. As of this writing, it has 55 member companies with over 750 members actively participating in the eight working groups. Anticipating the next phase of its architecture and communal evolution, UEC has added four new working groups: Storage, Management, Performance & Debug, and Compliance. These four working groups add to the existing Transport, Software, Link layer and PHY layer working groups. UEC has become an extremely strong force in AI and HPC networking, driving a tremendous amount of innovation in the Ethernet ecosystem.
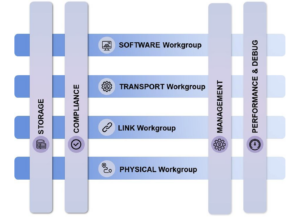
UEC is open to new members interested in joining the effort and contributing to the work.
Please monitor our website for news and for UEC v1.0 specifications later this year!